Automatic Youtube Transcript Generator - API Tutorial

Why bother extracting YouTube transcripts at scale?
YouTube is sitting on an enormous amount of spoken content, tutorials, interviews, commentary, product reviews. If you’re doing competitive research, building a training dataset, or just trying to understand what’s resonating in a niche, watching videos one by one isn’t going to cut it.
The good news: YouTube already generates auto-captions for most videos. The text is there, you just need a reliable way to get at it without resorting to screen recording or fragile browser hacks. That’s exactly what EnsembleData’s YouTube API is built for.
How YouTube stores transcript data
YouTube embeds caption information directly in each video’s metadata. Inside the response there’s a captions object containing playerCaptionsTracklistRenderer, which holds an array of captionTracks. Each track has a baseUrl, that’s the actual URL you can hit to download the full transcript text.
EnsembleData’s API hands you that metadata for any public video, caption URLs included. Once you have a baseUrl, you’ve got the transcript.
Grab a free API token at dashboard.ensembledata.com, then try this:
Prefer a different language? The API docs show the raw HTTP request format, anything that can make HTTP calls will work fine.
import requests
params = {
"id": "9lhtFHpNfms",
"alternative_method": True,
"token": "YOUR-TOKEN-HERE"
}
result = requests.get("https://ensembledata.com/apis/youtube/channel/get-short-stats", params=params).json()
data = result["data"]
print(data["captions"]["playerCaptionsTracklistRenderer"]["captionTracks"][0]["name"])
print(data["captions"]["playerCaptionsTracklistRenderer"]["captionTracks"][0]["baseUrl"])
Fetch that baseUrl and you’ll get back the raw transcript text:
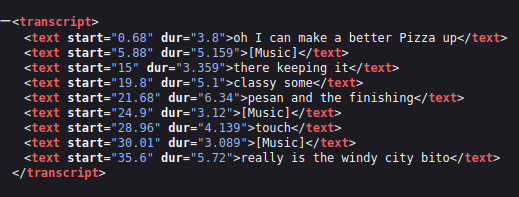
What you can actually do with this
A few situations where transcript extraction saves a ton of time:
- SEO research : pull transcripts from top-ranking videos in your niche and see what they’re covering, you might spot topics you’re missing entirely
- Training data : need labeled text for a classifier or summarization model? YouTube is a goldmine of domain-specific spoken content
- Content audits : managing a channel with hundreds of videos? Transcripts let you search and audit your own library programmatically
- Competitive intelligence : track what topics competitors keep coming back to without sitting through hours of footage
All of this is publicly available data, so there’s nothing sketchy about automating the collection.
Wrapping up
YouTube’s built-in caption system does most of the heavy lifting, you just need a clean way to access the metadata. EnsembleData’s API gives you that without dealing with rate limits, CAPTCHAs, or a scraper you have to babysit.
Take a look at the full API docs or reach out if you’re working on something specific and want to know if it’s a good fit.